
Centers News

Renaming of Data Analysis and Assessment Center (DAAC) to Data Analysis and Visualization Center (DAV Center)
The HPCMP is excited to announce that the Data Analysis and Assessment Center (DAAC) has been officially renamed the Data Analysis and Visualization Center (DAV Center). This new name more accurately reflects the center's mission within the program to advance data-driven insights and cutting-edge visualization techniques.
The updated name underscores our commitment to supporting the HPCMP community with innovative tools and expertise that bridge data analysis and visualization, driving impactful outcomes in research and development. We look forward to continuing our work under this new banner.
New Lead Selected for DAV Center
The HPCMP is pleased to announce that Christopher Lewis has been appointed as the new Lead of the Data Analysis and Visualization Center (DAV Center, formally DAAC). Chris brings over a decade of expertise in advanced visualization in support of the program.
With a Master’s degree in Computer Science focusing on Graphics and Visualization from Mississippi State University, Chris has demonstrated leadership and innovation throughout his career as a Visualization Scientist. Please join us in congratulating Chris on this well-deserved appointment and in supporting him as he leads the DAV Center into its next chapter of innovation and excellence.

New Supercomputer at Navy DoD Supercomputing Resource Center to Add Over 17 petaFLOPS of Computing Power to DoD Capability
The HPE Cray EX4000 system will address physics, AI, and ML applications for thousands of DoD High Performance Computing Modernization Program Users
The Department of Defense (DoD) High Performance Computing Modernization Program (HPCMP) recently completed a portion of its fiscal year 2023 investment in supercomputing capability supporting the DoD Science and Technology (S&T), Test and Evaluation (T&E), and Acquisition Engineering communities. The acquisition consists of a supercomputing system with corresponding hardware and software maintenance services. At 17.7 petaFLOPS, this system will replace three older supercomputers in the DoD HPCMP’s ecosystem and ensures that its aggregate supercomputing capability will remain above 100 petaFLOPS, with the latest available technology. This system significantly enhances the Program’s capability to support the Department of Defense’s most demanding computational challenges and includes the latest generation accelerator technology from AMD in the form of 128 AMD MI300A Accelerator Processing Units (APUs).
The system will be installed at the Navy DoD Supercomputing Resource Center (Navy DSRC) facility operated by the Commander, Naval Meteorology and Oceanography Command (CNMOC) at Stennis Space Center, Mississippi and will provide high performance computing capability for users from all services and agencies of the Department. The architecture of the system is as follows:
- An HPE Cray EX4000 system with 256,512 total compute cores, composed of AMD EPYC Genoa processors, 128 AMD MI300A Accelerator Processing Units (APUs), and 24 NVIDIA L40 GPGPUs connected by a 200 gigabit per second Cray Slingshot-11 interconnect and supported by 20 PB of usable Cray ClusterStor E1000 Lustre storage, including 2 PB of NVMe-based solid state storage, and 538 TiB of system memory.
The system is expected to enter production service in 2024. It will be named BLUEBACK in honor of the U.S. Navy submarine USS Blueback (SS-581) and will join existing Navy DSRC HPC systems NARWHAL, a 308,480-core HPE Cray EX supercomputer which is currently the largest unclassified supercomputer in the DoD and is named in honor of the USS Narwhal (SSN-671), and NAUTILUS, a 176,128-core Penguin TrueHPC supercomputer named in honor of the USS Nautilus (SSN-571).
About the DoD High Performance Computing Modernization Program (HPCMP)
The HPCMP provides the Department of Defense supercomputing capabilities, high-speed network communications and computational science expertise that enable DoD scientists and engineers to conduct a wide-range of focused research and development, test and evaluation, and acquisition engineering activities. This partnership puts advanced technology in the hands of U.S. forces more quickly, less expensively, and with greater certainty of success. Today, the HPCMP provides a comprehensive advanced computing environment for the DoD that includes unique expertise in software development and system design, powerful high performance computing systems, and a premier wide-area research network. The HPCMP is managed on behalf of the Department of Defense by the U.S. Army Engineer Research and Development Center located in Vicksburg, Mississippi.
For more information, visit our website at: https://www.hpc.mil.
About the Naval Oceanography and Meteorology Command (CNMOC)
Naval Oceanography has approximately 2,900 globally distributed military and civilian personnel, who collect, process, and exploit environmental information to assist Fleet and Joint Commanders in all warfare areas to guarantee the U.S. Navy’s freedom of action in the physical battlespace from the depths of the ocean to the stars.

Navy DSRC Adds New Supercomputer, Increases Computational Capability to Nearly 600,000 Compute Cores and over 30 PetaFLOPS
The Navy DoD Supercomputing Resource Center (Navy DSRC) is proud to announce the latest addition to its lineup of supercomputers: Nautilus.
Nautilus is a Penguin TrueHPC supercomputer with a peak performance of 8.2 petaFLOPS, 176,128 compute cores, 382 TB of memory, and 26 petabytes of storage. It completed its final testing in April 2023 and features 48 GPU nodes.
Including Nautilus, the Navy DSRC now has a total of six supercomputers, or high performance computing (HPC) systems, and is one of five DSRCs in the Department of Defense's High Performance Computing Modernization Program (HPCMP).
The Nautilus HPC system boasts an impressive configuration, including 1,352 compute nodes with up to 128 AMD EPYC Milan compute cores per node, 256 GB of memory per node, 16 NVIDIA A40 visualization nodes, 32 NVIDIA A100 Quad GPU AI/ML nodes, 26 petabytes of DDN storage (including 4.15 petabytes of NVMe storage), and a 200-Gbps NVIDIA Mellanox InfiniBand interconnect.
High performance computing plays a crucial role in many Department of Defense (DOD) projects, enabling scientists and researchers to achieve their science and technology objectives in various scientific disciplines, such as climate, weather, and ocean modeling, computational fluid dynamics, and computational chemistry. By using complex applications on these specialized HPC systems, they can predict the behavior of engineered systems in complex environments and analyze patterns in physical systems, enabling scientific discoveries and improvements in warfighting capabilities in a much faster, more efficient manner.
HPE Cray EX System Enhancements
The Navy DSRC has also increased the computational performance of its HPE Cray EX supercomputer, Narwhal. Narwhal now has an additional 18,176 cores, bringing its overall compute capacity to 308,480 compute cores via an additional 128 standard nodes and 14 large memory nodes with 1 TB per node.
Still the largest unclassified supercomputer in the Department of Defense, Narwhal now has 13.6 petaFLOPS of computing performance – that’s 13.6 quadrillion floating-point operations per second. Each flop represents a possible calculation, such as addition, subtraction, multiplication, or division.
With these enhancements, the Navy DSRC now offers its users a total of nearly 600,000 compute cores and over 30 petaFLOPS aggregate computational capability.

HPCMP standardizes AI/ML system allocation units.
For many years the HPCMP has used CPU core-hours as the unit of currency for HPC system project allocations. Systems equipped primarily with GPUs – called Machine Learning Accelerated (MLA) architectures – do not lend themselves well to allocations or utilization metrics based upon on core-hours. Consequently the HPCMP introduced the GPU-hour for MLA system allocations two years ago and has now standardized this quantity for its two MLA architectures, Onyx-MLA and SCOUT. Allocations on these two systems are made in FY 2023 by the Associate Director of Resource Management. Requests for allocations can be made by contacting your S/AAA and having the S/AAA request allocations for your project.
The latest AI/ML-focused system, Onyx-MLA, entered allocated service at ERDC DSRC on 29 April 2021.
As with SCOUT at ARL DSRC, since the primary purpose of this system is AI/ML workloads, the system is allocated on the basis of its GPU architecture. Onyx-MLA has four 10-MLA nodes with ten GPUs each and sixty 2-MLA nodes, each with two GPUs.
Total allocations are established as follows:
- Use of each 10-MLA node requires 10 GPU-hours per hour of use
- Use of each 2-MLA node requires 2 GPU-hours per hour of use
Total allocations available on Onyx-MLA are calculated based on 160 GPU-hours per hour (4 MLA-10 nodes x 10 GPUs + 60 MLA-2 nodes x 2 GPUs = 160 GPUs).
Total available Onyx-MLA allocations for FY23, based on 160 GPU-hours per hour, are 1,401,600 GPU-hours.
Users with an allocation on Onyx-MLA access it by submitting batch jobs from Onyx, as described in the Onyx MLA Quick Start Guide. Additional Onyx-MLA system technical details are below.
The 2-MLA nodes contain Tesla V100-SXM2-16GB GPUs. These GPUs use NVidia's SXM2 NVLink interconnect for extremely fast GPU-to-GPU communications and have 16GB of onboard memory.
The 10-MLA nodes contain Tesla V100- PCIE-32GB GPUs. These GPUs use the motherboard's slower PCIe bus for communications, but have double the onboard memory – 32GB.
The SCOUT system at ARL DSRC is also a GPU-intensive system targeted for AI/ML computations. There are two types of GPU nodes on SCOUT with different GPU types. There are 22 training nodes on SCOUT, each with 6 NVIDIA V100 PCle GPUs, and 128 inference nodes, each with 4 NVIDIA V100 T2 PCle GPUs. The total available SCOUT allocations for FY23 are 5,641,440 GPU-hours.

GitLab is Now Available For All HPCMP Users.
The HCPMP is pleased to announce the general availability of the HPCMP GitLab Service. The HPCMP GitLab Service enables collaboration and sharing of code and data among the HPCMP user community. Built on the open source GitLab server software, the service supports both the web interface for GitLab as well as Kerberos enabled GitLab SSH functionality for command-line operations. The GitLab Service allows for the creation of groups of users within the GitLab Service for sharing projects, managing and organizing users, and authorizing user access to various projects. Creation and maintenance of GitLab groups will be done by the GitLab administrator through a request to the HPC Helpdesk. GitLab projects and related repositories are restricted to unclassified code and data only. The GitLab project owner is responsible to protect their code and data by ensuring that their group members are authorized for access.
If you're an HPCMP user and want to use the GitLab service, register by authenticating to https://gitlab.hpc.mil. This creates your GitLab account in a locked state. To unlock it, submit a ticket to the HPC Desk ticket requesting activation.
To access the GitLab Service through the web interface simply navigate to the GitLab Server and authenticate using OpenID. To access the GitLab Service through SSH, use the SSH jump host, dsrcva8erdgit01.erdc.hpc.mil, instead of the GitLab server. The SSH jump host authenticates users using Kerberos credentials and then forwards SSH-based GitLab requests to the GitLab server. Users must first register their HPCMP accounts before using the SSH based interface. Access to the GitLab service is only allowed from DREN IP addresses. Some HPCMP resources, such as the Portal Appliances, provide web browsers that can be used to access the web interface.
For more information on accessing and using the HPCMP GitLab Service, please refer to the HPCMP GitLab Service User Manual.

HPC Help Desk Telephone Support Returns to Normal Hours.
The HPC Help Desk resumed normal on-site telephone operations on 28 September 2020. The Help Desk provides email and telephone support from 0800-2000 ET Monday-Friday. Please ensure you contact us via email as soon as possible if you are an S/AAA and your user needs a YubiKey sent to an address other than the address listed in the Portal to Information Environment (pIE).
Please stay safe and we thank you for your understanding and support as we work through this unprecedented situation together. We will keep you informed with status updates as they are available.
HPC Help Desk
Phone: 1-877-222-2039 or (937) 255-0679

The Vanguard Center, Centers, and PET Teams are excited to announce general availability of Singularity containers technology across all HPCMP compute systems. All allocated and many non-allocated systems now have Singularity version 2.6.1 available, and we are rolling out a major upgrade to version 3.5.3 over the next month. The Singularity capability will allow ordinary users to run (execute) applications built on other Linux versions/distributions inside a "Software Container" without modification, compiling, or library dependency issues. Version 3.5.3 includes the ability to directly run Open Container Initiative or Docker containers without conversion or performing a container 'build'. At present, performing container 'build' requires root/admin privilege on the building system (your laptop, workstation or cloud server), but the Containers Working Group is researching and developing mechanisms to allow ordinary users to build containers for DoD sensitive codes. Below is a brief summary of Containers technology. Additional information is available on centers.hpc.mil and https://training.hpc.mil, or you can contact the HPC Help Desk with your questions.
Introduction
Containers alleviate installation and portability challenges by packaging all of the dependencies of an application within a self-sustainable image, a.k.a a container. Linux container platforms such as Singularity and Docker allow you to install and use software within self-contained, portable, and reproducible environments. Linux containers allow users to:
- Use software with complicated dependencies and environment requirements
- Run an application container from the Sylabs Container Library or Docker Hub
- Use a package manager (like apt or yum) to install software without changing anything on the host system
- Run an application that was built for a different distribution of Linux than the host OS
- Run the latest released software built for newer Linux OS versions than that present on HPC systems
- Archive an analysis for long-term reproducibility and/or publication
What is a Software Container?
Put simply, a container consists of an entire runtime environment: an application, plus all its dependencies, libraries and other binaries, and configuration files needed to run it, bundled into one package. By containerizing the application platform and its dependencies, differences in OS distributions and underlying infrastructure are abstracted away.
Singularity is a tool for running containers on HPC systems, similar to Docker, and the first containerization technology supported across DSRC HPC-backed resources. Docker images are convertible to Singularity.
Why Singularity?
- Singularity is designed to run scientific applications on HPC-backed resources.
- Singularity is a replacement for Docker on HPC-backed resources.
- Singularity solves many HPC problems:
- Security: the user inside the container is the same as the one running the so no privilege escalation
- Ease of deployment: no daemon running as root on each node, a container is simply an executable
- Allows mounting local file systems or do bind mappings to access devices
- Run MPI and GPU HPC workflows with singularity containers
All HPCMP production systems have Singularity installed on login nodes and
compute resources. Reference containers for basic, MPI- and GPU-based
applications are in $SAMPLES_HOME.
Access Singularity by loading the "singularity" module:
$ module load singularity $ which singularity /p/work1/singularity/2.6.1/bin/singularity $ singularity --version 2.6.1-dist

STENNIS SPACE CENTER, Miss. — The Navy Department of Defense Supercomputing Resource Center (DSRC) is pleased to announce that it will receive the largest, most capable supercomputing system procured to date in the Department of Defense (DoD) High Performance Computing Modernization Program (HPCMP).
At a peak theoretical computing capability of 12.8 PetaFLOPS, or 12.8 quadrillion floating point operations per second, the multi-million dollar Cray Shasta supercomputer will be the first high-performance computing system in the HPCMP to provide over ten petaFLOPS of computing power to Department of Defense scientists, researchers, and engineers. It will be housed and operated at the Navy DSRC at Stennis Space Center in southern Mississippi.
That projected computing capability of the new system puts it in good company: today, it would be ranked among the top 25 most capable supercomputers in the world when compared to the current list at Top500.org, which ranks the world's most powerful non-distributed computer systems.
"The investment and increase in supercomputing power at the Navy DSRC at Stennis Space Center is absolutely critical to Naval Oceanography delivering future capability upgrades to global and regional ocean and atmospheric prediction systems, to include later this year the Navy's first Earth Systems Prediction Capability," said Commander, Navy Meteorology and Oceanography Command (NMOC) Rear Adm. John Okon.
"Naval Oceanography's ability to be the Department of Defense's authoritative source for characterizing and applying data of the physical battlespace into a decisive advantage for naval, joint and allied forces hinges on the continual upgrade and advancements in high-performance computing from the High Performance Computing Modernization Program."
The Cray Shasta supercomputer will feature 290,304 AMD EPYC (Rome) processor cores and 112 NVIDIA Volta V100 General-Purpose Graphics Processing Units (GPGPUs), interconnected by a 200 gigabit per second Cray Slingshot network. The system will also feature 590 total terabytes (TB) of memory and 14 petabytes (PB) of usable storage, including 1 PB of NVMe-based solid state storage.
The Navy DSRC and the HPCMP offer supercomputing capability to the DoD Science and Technology (S&T), Test and Evaluation (T&E), and Acquisition Engineering communities in support of various research efforts within the DoD, including aircraft and ship design, environmental quality modeling, and other projects to maintain the U.S. military's advantage over potential adversaries.
In particular, Navy DSRC supercomputers support climate, weather, and ocean modeling by NMOC, which assists U.S. Navy meteorologists and oceanographers in predicting environmental conditions that may affect the Navy fleet. Among other scientific endeavors, the new supercomputer will be used to enhance weather forecasting models; ultimately, this improves the accuracy of hurricane intensity and track forecasts.
The system is expected to be online by early fiscal year 2021.
"Our center is pleased to continue over twenty-five years of excellence in providing highly available supercomputers for the Department of Defense," said Christine Cuicchi, Director of the Navy DSRC. "While the new supercomputer itself will be quite the workhorse, it is complemented by a host of additional tools and services that the Navy DSRC offers in support of DoD users' research activities.
"Most people wouldn't expect Mississippi to be one of the premier locations for large-scale supercomputing," said Cuicchi, "but we are, and this new system will solidify our presence in the HPC community."
Navy DSRC currently provides almost 12 petaFLOPS of aggregate supercomputing capability to the Department of Defense. It is one of five DoD Supercomputing Resource Centers (DSRCs) in the DoD High Performance Computing Modernization Program (HPCMP), and is operated by NMOC on behalf of the DoD HPCMP.
About the HPCMP: The HPCMP provides the Department of Defense supercomputing capabilities, high-speed network communications and computational science expertise that enable DoD scientists and engineers to conduct a wide-range of focused research and development, test and evaluation, and acquisition engineering activities. This partnership puts advanced technology in the hands of U.S. forces more quickly, less expensively, and with greater certainty of success. Today, the HPCMP provides a comprehensive advanced computing environment for the DoD that includes unique expertise in software development and system design, powerful high performance computing systems, and a premier wide-area research network. The HPCMP is managed on behalf of the Department of Defense by the U.S. Army Engineer Research and Development Center located in Vicksburg, Mississippi.
Naval Oceanography has approximately 2,500 globally distributed military and civilian personnel, who collect, process and exploit environmental information to assist Fleet and Joint Commanders in all warfare areas to guarantee the U.S. Navy's freedom of action in the physical battlespace from the depths of the ocean to the stars.

The Department of Defense (DoD) High Performance Computing Modernization Program (HPCMP) is pleased to announce its newest supercomputing capability in support of the DoD Test and Evaluation (T&E), Acquisition Engineering, and Science and Technology (S&T) communities. IBM will provide the capability, to be delivered later in 2019, and consists of a supercomputing system housed in a shipping container with onboard power conditioning and cooling, along with the corresponding hardware and software maintenance services. The system will provide over 6 PetaFLOPS of single precision performance for training and inference machine learning workload and over 1 Petabyte of high performance, solid state storage for data analytic workloads. The system brings a significant capability to support militarily significant use cases that were not possible with supercomputers installed in fixed facilities.
The new supercomputer will initially be based at the U. S. Army Combat Capabilities Developmental Command Army Research Laboratory (ARL) DoD Supercomputing Resource Center (DSRC), and will serve users from all of the services and agencies of the Department. This "HPC in a Container" is designed to be deployable to the tactical edge; deployment opportunities to remote locations are currently being explored and evaluated.
The IBM system consists of:
- 22 nodes for machine learning training workloads, each with two IBM POWER9 processors, 512 GB of system memory, 8 nVidia V100 Graphical Processing Units with 32 GB of high bandwidth memory each, and 15 TB of local solid state storage.
- 128 nodes for inferencing workloads, each with two IBM POWER9 processors, 256 GB of system memory, 4 nVidia T4 Graphical Processing Units with 16 GB of high-bandwidth memory each, and 4 TB of local solid state storage.
- Three solid state parallel file systems, totaling 1.3 PB.
- A 100 Gigabit per second InfiniBand network as well as dual 10 gigabit Ethernet networks.
- Platform LSF HPC job scheduling integrated with a Kubernetes container orchestration solution.
- Integrated support for TensorFlow, PyTorch, Caffe in addition to traditional HPC libraries and toolsets including FFTW and Dakota.
- A shipping container-based facility with onboard uninterruptible power supply, chilled water cooling, and fire suppression systems.
The system is expected to be delivered later in 2019 and to enter production service shortly thereafter.

The Department of Defense (DoD) High Performance Computing Modernization Program (HPCMP) is pleased to announce new supercomputing capabilities supporting the DoD Science and Technology (S&T), Test and Evaluation (T&E), and Acquisition Engineering communities. The acquisition consists of two supercomputing systems with corresponding hardware and software maintenance services. At 10.6 petaFLOPs, this procurement will increase the DoD HPCMP's aggregate supercomputing capability to 57 petaFLOPs and over 1,000,000 cores. These systems significantly enhance the HPCMP’s capability to support DoD’s most demanding computational challenges, and include significant capabilities for artificial intelligence, data analytics, and machine learning.
The new supercomputers will be installed at the U. S. Army Combat Capabilities Developmental Command Army Research Laboratory (ARL) and U.S. Army Engineer Research and Development Center (ERDC) DoD Supercomputing Resource Centers (DSRCs), and will serve users from all of the services and agencies of the Department.
- The ARL DSRC in Aberdeen Proving Ground, Maryland, will receive a Cray CS500 system containing AMD EPYC (Rome) processors. The architecture of the system is as follows: A single system of 102,400 AMD EPYC "Rome" compute cores, 292 NVIDIA Volta V100 General-Purpose Graphics Processing Units (GPGPUs) supported by 350 TB of NVMe-based solid state storage, 446 terabytes of memory, and 15 petabytes of usable disk storage.
- The ERDC DSRC at Vicksburg, Mississippi, will receive a Cray CS500 system containing AMD EPYC (Rome) processors. The architecture of the system is as follows: A single system of 80,320 AMD EPYC "Rome" compute cores, 16 NVIDIA Volta V100 General-Purpose Graphics Processing Units (GPGPUs) supported by 30 TB of NVMe-based solid state storage, 320 terabytes of memory, and 11 petabytes of usable storage.
The systems are expected to enter production service early in calendar year 2020.

The High Performance Computing Modernization Program (HPCMP) User Group Meeting (UGM) will be held on 7-8 May 2019. It is sponsored by the U.S. Army Engineer Research and Development Center (ERDC), and will be held at the ERDC site in Vicksburg, MS. The UGM will provide attendees with a forum to exchange technical information and forge collaborations within the HPCMP community. It will offer plenary sessions, a keynote speaker and technical track sessions. Widespread participation across the HPCMP user community is encouraged.
- Large-scale Army HPC Applications
- Computational Electromagnetic & Acoustics
- Computational Sciences
- HPC Tool and Technologies in Data and Decision Analytics (DDA)
- Reduced-order Modeling
The deadline to register is 15 April 2019. No registration costs are required to attend UGM 2019. Optional snacks and lunches will be provided for a fee.
Abstracts are being accepted until 22 March 2019 and should be Distribution A. Presentations should be Distribution A, C, or D. Email abstract submissions and/or questions to UGM@hpc.mil
For more information and to register, please visit https://www.erdc.hpc.mil/UGM/index.html

The HPCMP is pleased to announce the completed integration of the new Center Wide File System (CWFS) at Navy DSRC as well as the planned rollout of new CWFSs across each of the other DSRCs over the next three months. The new CWFS is based on the IBM ESS platform with a Spectrum Scale (formerly GPFS) file system that provides four times the available storage space and four times the throughput as that on the current CWFS. The new CWFS went online at the Navy DSRC on June 20, 2018.
A 30-day migration period for users to migrate their $CENTER data from the existing CWFS to the new CWFS will be offered as each CWFS goes live. During this migration period, users will be able to access both CWFS file systems to copy data from the old CWFS to the new CWFS. Once the migration period has completed, users will no longer have access to any data on the old CWFS system and the old CWFS system will be taken offline and prepared for decommissioning. Data on the Utility Server that is located in $HOME and $WORK will be migrated to the new CWFS by the System Administration staff. Users will not be required to move their data in these file systems. Users will only need to migrate data that resides in $CENTER since that data is seen as transient and has a default 30 day retention period.
During the migration period, users can access the new /p/cwfs file system at the temporary mount point of /gpfs/cwfs to copy their data from /p/cwfs ($CENTER) on all systems. This will be a temporary mount point. When the migration period has expired, the new CWFS will assume the current CWFS mount point of /p/cwfs ($CENTER).
As mentioned previously, the new CWFS will provide a substantial increase in storage space. The existing file system for /u/work ($WORK) will remain the same size. The /p/cwfs ($CENTER) file system will be 4x larger and the /u/home ($HOME) file system will be increased to 64 TB from 19 TB. The table below outlines the current CWFS sizing compared with the new CWFS sizing.
| Current CWFS | New CWFS | ||
|---|---|---|---|
| File System | Size (TB) | File System | Size (TB) |
| /u/home ($HOME) | 19 | /u/home ($HOME) | 64 |
| /u/work ($WORKDIR) | 182 | /u/work ($WORKDIR) | 182 |
| /p/cwfs ($CENTER) | 728 | /p/cwfs ($CENTER) | 3300 |
Scrubbing policies will remain in effect and similar to the current CWFS:
| Current CWFS | New CWFS | ||
|---|---|---|---|
| File System | Days | File System | Days |
| /u/home ($HOME) | Exempt | /u/home ($HOME) | Exempt |
| /u/work ($WORKDIR) | 30 | /u/work ($WORKDIR) | 30 |
| /p/cwfs ($CENTER) | 30 | /p/cwfs ($CENTER) | 120 |
Quotas will also be applied to the new CWFS in similar fashion as the current CWFS:
| Current CWFS | New CWFS | ||
|---|---|---|---|
| File System | Quota (TB) | File System | Quota (TB) |
| /u/home ($HOME) | 10 | /u/home ($HOME) | 10 |
| /u/work ($WORKDIR) | 100 | /u/work ($WORKDIR) | 50 |
| /p/cwfs ($CENTER) | 200 | /p/cwfs ($CENTER) | 100 |
Estimated Go-Live Timeframe:
The Navy CWFS is serving as the pilot system for this project and the new CWFS went online on June 20, 2018. The ERDC CWFS and AFRL CWFS are scheduled to go live in the month of August 2018. ARL DSRC has two CWFS solutions currently in integration, with the unclassified instance and the classified instance both planned for go-live in August 2018. Lastly, MHPCC CWFS has a planned go live of September 2018.
Please be mindful of data that currently resides in $CENTER when moving to the new CWFS. While the storage size of the system is dramatically larger, users should only migrate data which is needed. As a reminder, no action is required for users with data in $HOME and $WORK on the Utility Server, as it will be migrated to the new CWFS by the System Administration staff.

The HPCMP PETTT team is excited to announce the new HPC training system is now available at https://training.hpc.mil. The HPC Training system includes New User Training modules, recent HPC Seminars recordings, Training Event recordings, and legacy content from the Online Knowledge Center in a modern, easy-to-use and easy-to-find structure. Every active HPCMP (non-ORS) user has an account. Just click the "Log in" button at the top-right corner, go to the HPCMP OpenID system to log in with CAC or Yubikey and you’ll return to the HPC Training site's home page.
We appreciate user feedback on the structure, organization, function, ease of use of the system as well as the quality and value of the information/content. Email hpctraining@hpc.mil for more information, to answer any questions or provide feedback.

Center-Wide File System
The Department of Defense (DoD) High Performance Computing Modernization Program (HPCMP) is pleased to announce the procurement of IBM Elastic Storage Server (ESS)-based systems as the next generation of Center-Wide File Systems (CWFSs). These new Center-Wide File Systems will replace the currently operational CWFSs and greatly increase the short-term data storage capability at the five DoD Supercomputing Resource Centers (DSRCs) within the HPCMP. The new CWFSs will be deployed and integrated at each DSRC during the 2018 calendar year.
The following sites will each receive an ESS system with quadruple the storage space (from 1 PB to 4 PB) and quadruple the storage throughput (from 10 Gb/sec to 40 Gb/sec) of today’s CWFS systems:
- The Air Force Research Laboratory (AFRL) DSRC
- The Army Research Laboratory (ARL) DSRC
- The Engineer Research and Development Center (ERDC) DSRC
- The Navy DSRC
ARL DSRC will receive an additional system to support classified computing.
The Vanguard Center at the Maui High Performance Computing Center (MHPCC) DSRC will receive a one petabyte IBM ESS system with double the storage throughput of their currently deployed CWFS (from 10 Gb/sec to 20 Gb/sec).
Each ESS system will consist of two racks containing the following components:
- IBM POWER-based server components
- Disk bays with 8 TB hard drives
- EDR-based InfiniBand fabric
In addition to replacing the existing CWFS, the HPCMP will upgrade the storage interconnect network devices. The current 10 Gigabit Ethernet-based Arista switch complex will be replaced with new 40 Gb/sec-based Arista switches, providing increased bandwidth between the new CWFS architecture and its storage clients.
Integration of the replacement Center-Wide File Systems and storage interconnect is currently underway at the Navy DSRC, which is serving as the pilot site. The CWFS installation schedule at the remaining DSRCs is being determined as of this writing. All systems are expected to be identical in configuration environment to enable a consistent user experience and will be operational in the second half of calendar year 2018.
HPC Portal Appliance
The Department of Defense (DoD) High Performance Computing Modernization Program (HPCMP) will soon be deploying HPC Portal Appliances (PA) to each of its five DoD Supercomputing Resource Centers (DSRCs). The Portal Appliance will provide a platform for the hosting and execution of the HPC Portal Services. The HPC Portal Services are currently hosted on the existing Utility Servers at each DSRC and will be migrated to the new PA platform.
The PA is primarily composed of 11 HPE servers with the following attributes that will provide web and virtual application services for the portal users:
- HPE DL380 Gen10 Servers
- Intel Skylake based CPUs
- NVIDIA Tesla P40 GPUs
- 10 Gigabit Ethernet Interconnect
There will be a total of six full portal appliances deployed with each DSRC receiving one PA; the Army Research Laboratory (ARL) DSRC will receive two—one for unclassified and one for classified computing. The new PAs will have identical configurations to enable a consistent user experience and will be operational in the second half of 2018.
Distribution A: Approved for Public release; distribution is unlimited.

The Department of Defense (DOD) High Performance Computing Modernization Program (HPCMP) completed its fiscal year 2017 investment in supercomputing capability supporting the DoD Science and Technology (S&T), Test and Evaluation (T&E), and Acquisition Engineering communities. The acquisition consists of seven supercomputing systems with corresponding hardware and software maintenance services. At 14 petaFLOPs, this procurement will increase the DoD HPCMP's aggregate supercomputing capability to 47 petaFLOPs. These systems significantly enhance the Program's capability to support the Department of Defense's most demanding computational challenges.
The new supercomputers will be installed at the Air Force Research Laboratory (AFRL) and Navy DoD Supercomputing Resource Centers (DSRCs), and will serve users from all of the services and agencies of the Department.
The AFRL DSRC in Dayton, Ohio, will receive four HPE SGI 8600 systems containing Intel Xeon Platinum 8168 (Skylake) processors. The architectures of the four systems are as follows:
- A single system of 56,448 Intel Platinum Skylake compute cores and 24 NVIDIA Tesla P100 General-Purpose Graphics Processing Units (GPGPUs), 244 terabytes of memory, and 9.2 petabytes of usable storage.
- A single system of 13,824 Intel Platinum Skylake compute cores, 58 terabytes of memory, and 1.6 petabytes of usable storage.
- Two systems, each consisting of 6,912 Intel Platinum Skylake compute cores, 30 terabytes of memory, and 1.0 petabytes of usable storage.
The Navy DSRC at Stennis Space Center, Mississippi, will receive three HPE SGI 8600 systems containing Intel Xeon Platinum 8168 (Skylake) processors. The architectures of the three systems are as follows:
- Two systems, each consisting of 35,328 Intel Platinum Skylake compute cores, 16 NVIDIA Tesla P100 GPGPUs , 154 terabytes of memory, and 5.6 petabytes of usable storage.
- A single system consisting of 7,104 Intel Platinum Skylake compute cores, four NVIDIA Tesla P100 GPGPUs, 32 terabytes of memory, and 1.0 petabytes of usable storage.
The systems are expected to enter production service in the second half of calendar year 2018.
About the DOD High Performance Computing Modernization Program (HPCMP)
The HPCMP provides the Department of Defense supercomputing capabilities, high-speed network communications and computational science expertise that enable DOD scientists and engineers to conduct a wide-range of focused research and development, test and evaluation, and acquisition engineering activities. This partnership puts advanced technology in the hands of U.S. forces more quickly, less expensively, and with greater certainty of success. Today, the HPCMP provides a comprehensive advanced computing environment for the DOD that includes unique expertise in software development and system design, powerful high performance computing systems, and a premier wide-area research network. The HPCMP is managed on behalf of the Department of Defense by the U.S. Army Engineer Research and Development Center located in Vicksburg, Mississippi.
For more information, visit our website at: https://www.hpc.mil.

The Maui High Performance Computing Center, as one of the High Performance Computing Modernization Program's (HPCMP) Department of Defense Supercomputing Resource Centers (DSRC), contracted with IBM to deliver a cluster solution based on IBM's POWER8 server with high-performance, high-bandwidth, NVIDIA GP100 graphical processing units (GPUs). The total life-cycle investment is valued at $2 million.
The IBM cluster will conjointly provide 458,752 GPU cores integrated with NVLink 1.0. NVLink is a high-bandwidth interconnect that enables communication between a GPU and CPU, and also between GPUs. NVLink supports data transfer rates much greater than that of PCIe. This mitigates the bottleneck of data transfers between processing units, thus resulting in greater application performance. The IBM cluster will be named Hokule'a, which means "star of gladness" in Hawaiian, and refers to a star used by ancient Hawaiians in wayfinding techniques of celestial navigation.
Utilizing the GPUs, Hokule'a will provide over 690 TFLOPs of supercomputing. As its name implies, it will be used as a test system to evaluate the performance of this novel architecture for DoD-specific software. The system was delivered in December of 2016.

The Department of Defense (DoD) High Performance Computing Modernization Program (HPCMP) completed its fiscal year 2016 investment in supercomputing capability supporting the DoD Science and Technology (S&T), Test and Evaluation (T&E), and Acquisition Engineering communities. The acquisition consists of three supercomputing systems with corresponding hardware and software maintenance services. At almost 10 petaFLOPs, this procurement will increase the DoD HPCMP's aggregate supercomputing capability to 31.1 petaFLOPs.
The new supercomputers will be installed at the Army Research Laboratory (ARL) and Engineer Research and Development Center (ERDC) DoD Supercomputing Resource Centers (DSRCs), and will serve users from all of the services and agencies of the Department:
- The Army Research Laboratory DSRC in Aberdeen, Maryland, will receive two SGI ICE X systems containing Intel Xeon "Broadwell" processors and NVIDIA Tesla K40 General-Purpose Graphics Processing Units (GPGPUs). These systems will consist of 33,088 and 73,920 "Broadwell" compute cores respectively, 32 GPGPUs each, 200 and 252 terabytes of memory respectively, 3.5 and 12 petabytes of disk storage respectively, and will provide 1.2 and 2.6 petaFLOPS of peak computing capability each.
- The US Army Corps of Engineers Engineer Research and Development Center DSRC in Vicksburg, Mississippi, will receive a Cray XC40 system containing Intel Xeon "Broadwell" processors, Intel Knights Landing (KNL) Many Integrated Core processors, and NVIDIA Tesla K40 GPGPUs. The system will consist of 126,192 "Broadwell" compute cores, 540 KNL nodes (64 cores each, 34,560 cores total), 32 GPGPUs, 437 terabytes of memory, 16 petabytes of disk storage, and will provide 6.05 petaFLOPS of peak computing capability.
The systems are expected to enter production service in the first half of calendar year 2017.

The Army Research Laboratory DoD Supercomputing Resource Center (ARL DSRC) has recently partnered with Intel and SGI to deploy a testbed, the Intel Knights Landing cluster, consisting of 28 nodes, in the DoD High Performance Computing Modernization Program (HPCMP). This testbed will give HPCMP users the opportunity to begin refactoring their applications in preparation for a larger, 540-node KNL partition on a production system to be installed at the Engineer Research and Development Center DoD Supercomputing Resource Center (ERDC DSRC) in 2017. The testbed has an Intel Omni-Path Interconnect, as well as Mellanox EDR InfiniBand interconnects, and is available for porting and benchmarking applications. Production computations are not currently supported due to frequent configuration changes.
Contact the HPC Helpdesk for more information.

The Navy DSRC has established the Flexible Home & Job Management project in order to provide the users of the Cray XC30 systems Armstrong and Shepard with additional capabilities. The Center hopes that this project will lead to a better overall user experience for computing on the separate systems.
The Flexible Home & Job Management project consists of three layers. The first layer is a central login / job submission point. Users will be able to login to a central set of nodes for managing data and submitting jobs. The second layer leverages Altair.s PBSPro capability known as peer scheduling to allow jobs to flow from the central job submission point to Armstrong or Shepard and between Armstrong and Shepard themselves. The third layer is a centralized storage component that will provide users with a common home directory for both systems.

In the High Performance Computing Modernization Program, our goal is to provide our users with nothing less than a world-class HPC experience. Providing such an experience is a world-class challenge, and we employ talented and dedicated experts who strive for that goal every day. In trying to meet this challenge, however, we've realized one very important thing. Keeping up with the relentless pace of science, technology, and thousands of dedicated researchers is a herculean task, which will only be met by drawing upon the collective experience of the most intelligent, talented, creative, and driven people in the world... our users!
Because no one understands users' problems better than users themselves, the HPCMP chartered the User Advocacy Group (UAG) in 2002 to provide a way for users to influence policies and practices of the program by helping HPCMP leadership to better understand their changing needs. The UAG serves as an advocacy group for all HPCMP users, advising the Program Office on policy and operational matters from the user perspective. The UAG seeks to encourage efficient and effective use of HPCMP resources by fostering cooperation and teamwork among users and all program participants, and providing a forum for discussion and exchange of ideas.
As a user, the UAG is your loudest voice within the program. UAG representatives from across the DoD, many of whom are experienced users, provide a wealth of experience and deep technical understanding to HPCMP leadership, helping to improve the user experience for everyone.
You are invited to participate in this effort by contacting your UAG representative with your needs, concerns, and ideas. To find your representative, see the UAG roster on the User Dashboard. While you're there, you can also view the UAG Charter and the Minutes of past UAG meetings to gain a better understanding of how the UAG works.
We look forward to hearing from you.

SRD v2.1.1 has been released. This is an optional upgrade, and existing v2.1 users are unaffected. Visit the What's New page for an overview of what changed.
SRD allows any active HPCMP researcher to launch a Gnome desktop from a DSRC Utility Server, and the remote desktop is displayed on the user's client platform (Linux, Mac, or Windows). With this desktop, the user can run any graphical software installed on the Utility Server - MatLab, TecPlot, EnSight, etc. The SRD utility is a smart combination of hardware and software. It is highly optimized for graphics processing, remote rendering, and efficiently streaming the results back to your desktop. The net result: rapid 3-D visualization at the price of a 2-D data stream. Visit the SRD home page for full instructions on getting started.

As of May 18th, the HPC Help Desk has replaced CCAC.
In order to more accurately describe the services provided, the Consolidated Customer Assistance Center (CCAC) has been renamed the "HPC Help Desk." This change is effective immediately. Access to the HPC Help Desk ticket system has changed from its old location to the new https://helpdesk.hpc.mil/hpc. Accordingly, the email address to contact the HPC Help Desk has become help@helpdesk.hpc.mil. The old URL and email address will remain available with auto forwarding and redirection for a period of time, but you are encouraged to update your bookmarks and contacts now. The phone number, 1-877-222-2039, will remain the same.

ARL's newest HPC system, Excalibur, has over 101,000 cores and a theoretical peak speed of 3.7 petaFLOPS.
Recently acquired by the Department of Defense (DOD) High Performance Computing Modernization Program (HPCMP), the Cray XC40 supercomputer located at the Army Research Laboratory DOD Supercomputing Resource Center (ARL DSRC) debuted at number 19 on the November 2014 TOP500 list. The TOP500 list tallies the world's most powerful supercomputers and is published in June and November each year. ARL DSRC recently took delivery of this new HPC system, named Excalibur.
The system will complement a cadre of other HPC resources at the ARL DSRC. Excalibur will be one of the largest supercomputers installed to date in the HPCMP, boasting 101,184 cores augmented with 32 NVIDIA Tesla K40 GPGPUs. The system has a theoretical peak of over 3.7 petaFLOPS, 400 TB of memory, and 122 TB of solid-state disk (or .flash. storage). Excalibur will serve as a key HPC resource for the DOD Research, Development and Test and Evaluation communities.
The Department of Defense (DOD) High Performance Computing Modernization Program (HPCMP) just completed its fiscal year 2015 investment in supercomputing capability supporting the DOD science, engineering, test and acquisition communities. The total acquisition is valued at $73.8 million, including acquisition of four supercomputing systems with corresponding hardware and software maintenance services. At 9.92 petaFLOPS, this procurement will increase the HPCMP's aggregate supercomputing capability from 16.5 petaFLOPS to 26.4 petaFLOPS.
"The acquisition of these four systems completes an historic year for the HPCMP," said Christine Cuicchi, HPCMP associate director for High Performance Computing (HPC) centers. "We have now purchased more than $150 million of supercomputers within the 2014 calendar year. This previously unmatched expansion in capability — which nearly quintuples our pre-2014 capacity of 5.38 petaFLOPS to 26.4 petaFLOPS — will give our users another 577,000 compute cores on which to perform groundbreaking science and realize previously impossible discoveries in DOD research."
The four purchased systems will collectively provide 223,024 cores, more than 830 terabytes of memory, and a total disk storage capacity of 17.4 petabytes. This competitive government acquisition was executed through the U. S. Army Engineering and Support Center in Huntsville, Alabama, which selected systems from Silicon Graphics Federal, LLC, and Cray, Inc.
The new supercomputers will be installed at two of the HPCMP's five DOD Supercomputing Resource Centers (DSRCs), and will serve users from all Defense Department services and agencies:
The Air Force Research Laboratory DSRC at Wright-Patterson Air Force Base, Ohio, will receive an SGI ICE X system, based on the 2.3-GHz Intel Xeon E5-2699v3 ("Haswell-EP") processors. The system will be named "Thunder" and consist of:
- 125,888 compute cores
- 356 Intel Xeon Phi 7120P accelerators
- 356 NVIDIA Tesla K40 GPGPUs
- 443 terabytes of memory
- 12.4 petabytes of storage
- 5.66 petaFLOPS of peak computing capability
The Navy DSRC of the Naval Meteorology and Oceanography Command at Stennis Space Center, Mississippi, will receive three Cray XC40 systems containing 2.3 GHz Intel Xeon E5-2698v3 ("Haswell-EP") processors. The systems will be named "Bean," "Conrad," and "Gordon," in honor of the Apollo 12 astronauts Alan Bean, Pete Conrad, and Richard F. Gordon, Jr., all of whom were also naval aviators. Two larger systems will each contain:
- 50,208 compute cores
- 168 Intel Xeon Phi 5120D accelerators
- 197 terabytes of memory
- 2.29 petabytes of storage
- 2.0 petaFLOPS of peak computing capability
A third smaller system will contain:
- 6,720 compute cores
- 24 Phi accelerators
- 27 terabytes of memory
- 420 terabytes of storage
- 260 teraFLOPS peak computing capability
Combined, the Navy DSRC will add 107,136 compute cores and 4.26 petaFLOPS of capability to the DSRC.
The HPCMP enables advanced computing for the DOD's science and engineering communities, and serves as an innovation enabler. HPC is employed in a broad range of diverse application areas in the DOD including fluid dynamics, structural mechanics, materials design, space situational awareness, climate and ocean modeling, and environmental quality.

The Department of Defense (DOD) High Performance Computing Modernization Program (HPCMP) just completed its fiscal year 2014 investment in supercomputing capability supporting the DOD science, engineering, test and acquisition communities. The total acquisition is valued at $65 million, including acquisition of two supercomputing systems with corresponding hardware and software maintenance services. At 8.4 petaFLOPs, this procurement more than doubles the HPCMP's aggregate supercomputing capability, increasing from 8.1 petaFLOPs to 16.5 petaFLOPs.
"Supercomputing is a critical enabling technology for the DOD as it continues vital work to improve both the safety and performance of the U.S. military," said John West, director of the HPCMP. "These newly acquired systems ensure that scientists and engineers in the DOD's research, development, test and evaluation communities will continue to be able to take advantage of a robust computing ecosystem that includes the best computational technologies available today."
The two purchased systems will collectively provide nearly 227,000 cores, more than 850 terabytes of memory, and a total disk storage capacity of 17 petabytes. This competitive government acquisition was executed through the U.S. Army Engineering and Support Center in Huntsville, Alabama, which selected systems from both Silicon Graphics Federal, LLC, and Cray, Inc.
"The increase in computational capability will dramatically improve the speed at which our scientists and engineers are able to complete their work," said Christine Cuicchi, HPCMP associate director for HPC centers. "These systems are also designed to advance DOD's scientific visualization capabilities to manage the vast amounts of data being produced on these systems, providing new opportunities for discovery in numerous areas of research."
The new supercomputers will be installed at two of the HPCMP's five DOD Supercomputing Resource Centers (DSRCs), and will serve users from all of the services and agencies of the Defense Department:
- The Army Research Laboratory DSRC in Aberdeen, Maryland, will receive a Cray XC40 system containing 2.3-GHz Intel Xeon E5-2698 v3 ("Haswell-EP") processors and NVIDIA Tesla K40 General-Purpose Graphics Processing Units (GPGPUs). This system will consist of 101,312 compute cores, 32 GPGPUs, and 411 terabytes of memory, and will provide 3.77 petaFLOPS of peak computing capability.
- The U.S. Army Engineer Research and Development Center DSRC in Vicksburg, Mississippi, will receive an SGI ICE X system containing 2.3-GHz Intel Xeon E5-2699 v3 ("Haswell-EP") processors and NVIDIA Tesla K40 GPGPUs. The system will consist of 125,440 compute cores, 32 GPGPUs, and 440 terabytes of memory, and will provide 4.66 petaFLOPS of peak computing capability.
Delivery of the new systems is expected in the spring of 2015, with general availability to users in the summer.

The Department of Defense (DoD) High Performance Computing Modernization Program (HPCMP) has made significant progress toward improving access to supercomputing for the DoD research, development, test and evaluation (RDT&E) community through the use of a web-enabled portal. The combined efforts of the development and testing teams at the Maui High Performance Computing Center and the U.S. Army Engineer Research and Development Center (ERDC), as well as the deployment team at the Navy's DoD Supercomputing Resource Center (DSRC), have resulted in a new, easy-to-use, web-based portal which provides access to DoD supercomputers and scientific visualization tools via a standard web browser. The High Performance Computing (HPC) portal requires no user-installed software, and provides a secure unified access point protected by multi-factor authentication using a common access card or YubiKey token. The portal is available at https://centers.hpc.mil/portal. Prior to the advent of this HPC service, workstations with software installation privileges as well as significant network bandwidth, to allow large and frequent file transfers to/from HPC systems, were required to make effective use of HPC resources. The HPC Portal removes the requirement for additional local software, and co-locates the workflow and compute software with the computed datasets, reducing data movement and potentially improving the time-to-solution and time-to-discovery for the user.
"The HPC portal provides a much-needed means of simplifying the workflow for the user community," said Tom Dunn, director of the Navy DSRC.
This innovative service is fully operational and available on the Navy DSRC's supercomputer systems, Kilrain and Haise. Each system is a 400 TFLOP/s IBM iDataPlex, containing 40 TB of memory and over 1,200 compute nodes, each with 16 cores, yielding more than 19,500 compute cores for the system as a whole.
More information on the HPC portal can be found at https://www.mhpcc.hpc.mil/portal.
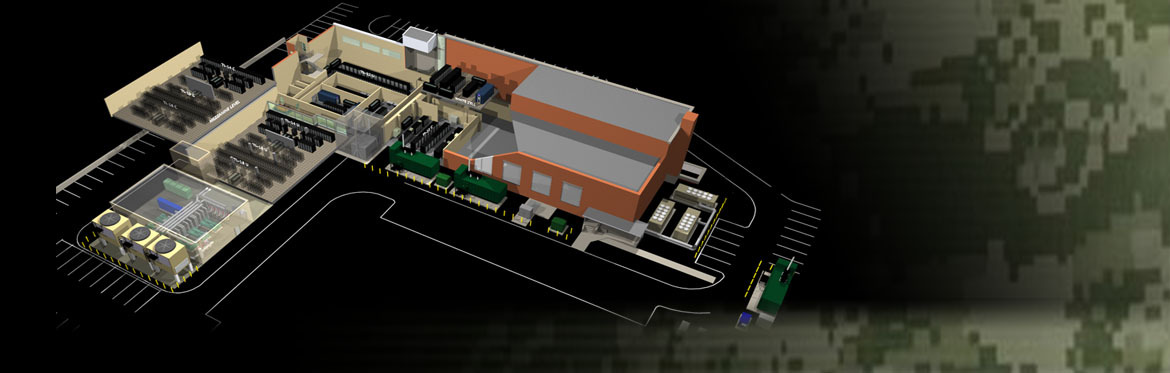
ARL is making major renovations and upgrades to the ARL Supercomputing Research Center facility to prepare the ARL DSRC for Technology Insertion for fiscal year 2014 (TI-14) systems arrivals as well as scaling the Center's High Performance Computing (HPC) infrastructure for future systems.
Building on the initial TI-12 requirements, the facility expansion was scoped to take advantage of the available space and infrastructure to build out the facility to meet HPC system needs through 2018. Plans are to increase commercial power capacity to 12 Megawatts, generator power to 12 Megawatts, cooling capacity to 2600 tons, and UPS protection to 8 Megawatts.

The Department of Defense (DoD) High Performance Computing Modernization Program (HPCMP) has just completed its fiscal year 2013 investment in supercomputing capability supporting the DoD science, engineering, test and acquisition communities. The total acquisition is valued at $50 million, including acquisition of multiple supercomputing systems and hardware, as well as software maintenance services. At nearly three petaFLOPS of computing capability, the acquisition constitutes a more than 50 percent increase in the DoD HPCMP.s current peak computing capability.
The supercomputers will be installed at two of the HPCMP's five DoD Supercomputing Resource Centers (DSRCs), and will serve users from all of the services and agencies of the Department.
- The Air Force Research Laboratory DSRC at Wright-Patterson Air Force Base, Ohio, will receive a 1.2 petaFLOPs Cray XC30 system built upon the 2.7-GHz Intel Xeon E5-2697 v2 ("Ivy Bridge EP") processor. This system consists of 56,112 compute cores and 150 terabytes of memory.
- The Navy DSRC, Naval Meteorology and Oceanography Command, located at Stennis Space Center, Mississippi, will receive two 0.75 petaFLOPs Cray XC30 systems built upon the 2.7-GHz Intel Xeon E5-2697 v2 processor and the 1.05-GHz Intel Xeon Phi Coprocessor 5120D. These two systems are identical; each consisting of 29,304 compute cores, 7,440 coprocessor cores, and 78 terabytes of memory. The systems are designed as sister-systems to provide continuous service during maintenance outages.
Delivery of the new systems is expected in the spring of 2014, with general availability to users in the summer.

The HPCMP Centers Team is pleased to announce the availability of Intel Xeon Phi accelerated nodes on Navy DSRC IBM iDataPlex systems HAISE and KILRAIN. Intel Xeon Phis, also known as many integrated cores (MICs), can each support up to 240 threads of concurrent execution. A detailed Intel Xeon Phi Guide is available on the Navy DSRC website at: https://www.navydsrc.hpc.mil/docs/xeonPhiGuide.html
Users will be able to access the nodes via the phi64 queue on each system. PBS jobs submitted to the phi64 queue will continue to be charged based on the usage of a standard compute node (# of nodes * 16 cores * # of hours). If you would like access to the phi64 queue, please send a brief note requesting access to dsrchelp@navydsrc.hpc.mil.
These nodes are comprised of both a compute node and an accelerator node. Each accelerated compute node contains two 8-core 2.6-GHz Intel Sandy Bridge processors, identical to those in the rest of the system, and 64 GB of memory. Each Xeon Phi co-processor node contains two Intel Xeon Phi 5110P co-processors, each composed of 60 cores and 8 GB of internal memory. Each Xeon Phi core supports up to 4 execution threads, allowing for potentially extensive parallelism.
In order to properly support compilation of Intel Xeon Phi codes, the Intel Compiler Suite and Intel Math Kernel Library (MKL) modules will both be defaulted to version 13.1 on Haise and Kilrain.
Please note: Intel Xeon Phi nodes on Haise and Kilrain currently only support offload mode and native mode.
In offload mode, code runs on the standard compute node portion of a Phi node and offloads segments of execution to the co-processor portion. For example, an MPI code with offload directives within it could run on multiple accelerated nodes, using the Intel Xeon Phi portion of each node to potentially speed up calculations.
In native mode, code runs directly on the co-processor node. Currently, MPI codes running in native mode are limited to a single Phi node. However, in the next several months Mellanox should release an update to its version of OFED, which will support native execution of MPI codes across multiple Intel Xeon Phi nodes.
For more information about developing code for the Intel Xeon Phi, including webinars, please see: http://software.intel.com/mic-developer.
Users are invited to report problems and direct requests for unclassified assistance to the Consolidated Customer Assistance Center (CCAC) at 1-877-222-2039 or by E-mail to help@ccac.hpc.mil.

The HPCMP recently upgraded the existing PGI Compiler licenses on the DSRC utility servers to support OpenACC directives. Programmers can accelerate applications on x64+accelerator platforms by adding OpenACC compiler directives to existing high-level standard-compliant Fortran, C and C++ programs and then recompiling with appropriate compiler options. The only installed PGI version on the utility servers that supports Acceleration/OpenACC is 13.7. All other installed versions support only the original base compiler license. Information on PGI Accelerator compilers can be found at the following link: http://www.pgroup.com/resources/accel.htm
The new HPC Centers website, https://centers.hpc.mil, is your resource for all information and documentation related to HPC systems, tools, and services available at the five DSRCs and within the High Performance Computing Modernization Program (HPCMP). This website replaces http://ccac.hpc.mil, which is no longer in service.
The User Dashboard has been developed to provide all authorized users holding a valid HPCMP account a personalized look at up-to-date information pertaining to your user accounts on all of the HPC systems to which you have access within the Program. The Dashboard also provides documentation that requires authentication to view, including information about our classified systems.

The 150,912 Core Cray XE6 (Garnet) is open for logins and batch jobs submission. The consolidation of Raptor, Chugach and the original Garnet plus additional disk racks makes Garnet the largest HPC system in the High Performance Computing Modernization Program.
Garnet is a capability computing system and has been tailored to run large jobs with its maximum job size of 102,400 cores and reduced wall time limits for large jobs to increase throughput. Running very large jobs has it challenges, with IO being one of the most difficult to contend with. Guidance and tools to help maximize IO performance of large jobs are found on the ERDC DSRC website:
- p" rel="noopener noreferrer">Using ADIOS, a flexible IO library
- IO tips from Cray, Inc.
- A Checkpoint restart introduction
- Optimizing code for AMD Interlagos

The Air Force Research Laboratory (AFRL) DoD Supercomputing Resource Center (DSRC), one of the five supercomputing centers in the Department of Defense High Performance Computing Modernization Program (HPCMP), is proud to announce the transition to full production of its newest supercomputer for the Department of Defense. The new SGI ICE X supercomputer, named "Spirit" in honor of the B-2 Stealth Bomber, is located at Wright-Patterson Air Force Base in Dayton, Ohio.
Installation of the new system expands the installed supercomputing capability of the AFRL DSRC by 1.415 quadrillion floating point operations per second (petaFLOPS), making it one of the top 20 fastest computers in the world. The new system will support research, development, test and evaluation in a diverse array of disciplines ranging from aircraft and ship design to microelectronics and protective systems. Read More >

The HPCMP recently completed the installation, integration, and testing of six IBM iDataPlex systems, and all are now in full production for DoD scientists and engineers. Three of the systems, named haise, kilrain, and cernan, are located in the Navy DSRC at the Navy Meteorology and Oceanography Command, Stennis Space Center, Mississippi. Two of the systems, named pershing and hercules, are located at the Army Research Laboratory (ARL) DSRC, Aberdeen Proving Grounds, Maryland. The final system, named riptide, is located at the Maui High Performance Computing Center (MHPCC) DSRC in Kihei, Hawaii
Each system is based on the Intel Sandy Bridge E2670 processor, which runs at 2.6 GHz and features TurboMode and Hyperthreading. Moreover, the system features RedHat Enterprise Linux, the IBM General Parallel Filesystem (GPFS), and a Mellanox FDR-10 Infiniband interconnect. The Navy DSRC systems are additionally fitted with Intel Xeon Phi 5110P coprocessors based on Intel Many Integrated Core (MIC) architecture, enabling more efficient performance for highly-parallel applications.
The table below presents specific system details for the HPCMP IBM iDataPlex systems.
| System | Compute Nodes |
Compute Cores |
Memory per Node |
Peak Performance |
|---|---|---|---|---|
| Haise | 1,176 | 18,816 + 24phi | 32 GB | 435 TFLOPS |
| Kilrain | 1,176 | 18,816 + 24phi | 32 GB | 435 TFLOPS |
| Cernan | 248 + 41 | 3,968 + 641 | 32 GB or 256 GB1 | 84 TFLOPS |
| Pershing | 1,092 + 1681 | 17,472 + 2,6881 | 32 GB or 64 GB1 | 420 TFLOPS |
| Hercules | 1,092 | 17,472 | 64 GB | 360 TFLOPS |
| Riptide | 756 | 12,096 | 32 GB | 252 TFLOPS |
1 - Large memory nodes
The HPCMP is delighted to offer these new systems - providing an aggregate of one petabyte of peak computational power - to the DoD Science and Technology (S&T) and Test and Evaluation (T&E) communities. To request an account, contact the HPCMP Consolidated Customer Assistance Center at help@ccac.hpc.mil.

Navy DSRC Establishes HPC System Names and Honors NASA Astronaut and Former Naval Aviator Fred Haise at Ceremony
The Navy DoD Supercomputing Resource Center (DSRC), one of the five supercomputing centers in the Department of Defense High Performance Computing Modernization Program (HPCMP), recently added three new supercomputers to its operations. The three IBM iDataPlex systems, installed in the fall of 2012 and operational in January, tripled the installed capacity of the Navy DSRC.
The new supercomputers, located at the John C. Stennis Space Center in Mississippi, are named after NASA astronauts who have served in the Navy. At a dedication ceremony in February, one of those computers was dedicated in honor of naval aviator and Apollo 13 astronaut Fred Haise, who attended the ceremony. Read More >

The Department of Defense (DoD) High Performance Computing Modernization Program (HPCMP) was recently recognized by the U.S. Army chief of engineers in the Awards of Excellence program for excellence in sustainability, design and construction. A team comprised of representatives from the HPCMP's five DoD Supercomputing Resource Centers (DSRCs) was awarded the U.S. Army Corps of Engineers (USACE) Green Innovation Award for recognizing an innovation or idea with clear potential to transform the federal community's overall energy and environmental performance. The award is presented to an individual or team for the development and execution of a novel product, project, program, design or revolutionary idea that promotes sustainability in the federal government in an area relevant to the USACE mission. The DSRCs created an interagency community of practice (COP) team, the Green Team, that meets monthly to share best practices in supercomputing facilities operation and to plan energy awareness initiatives. Read More >